ai
Mental Health Screening
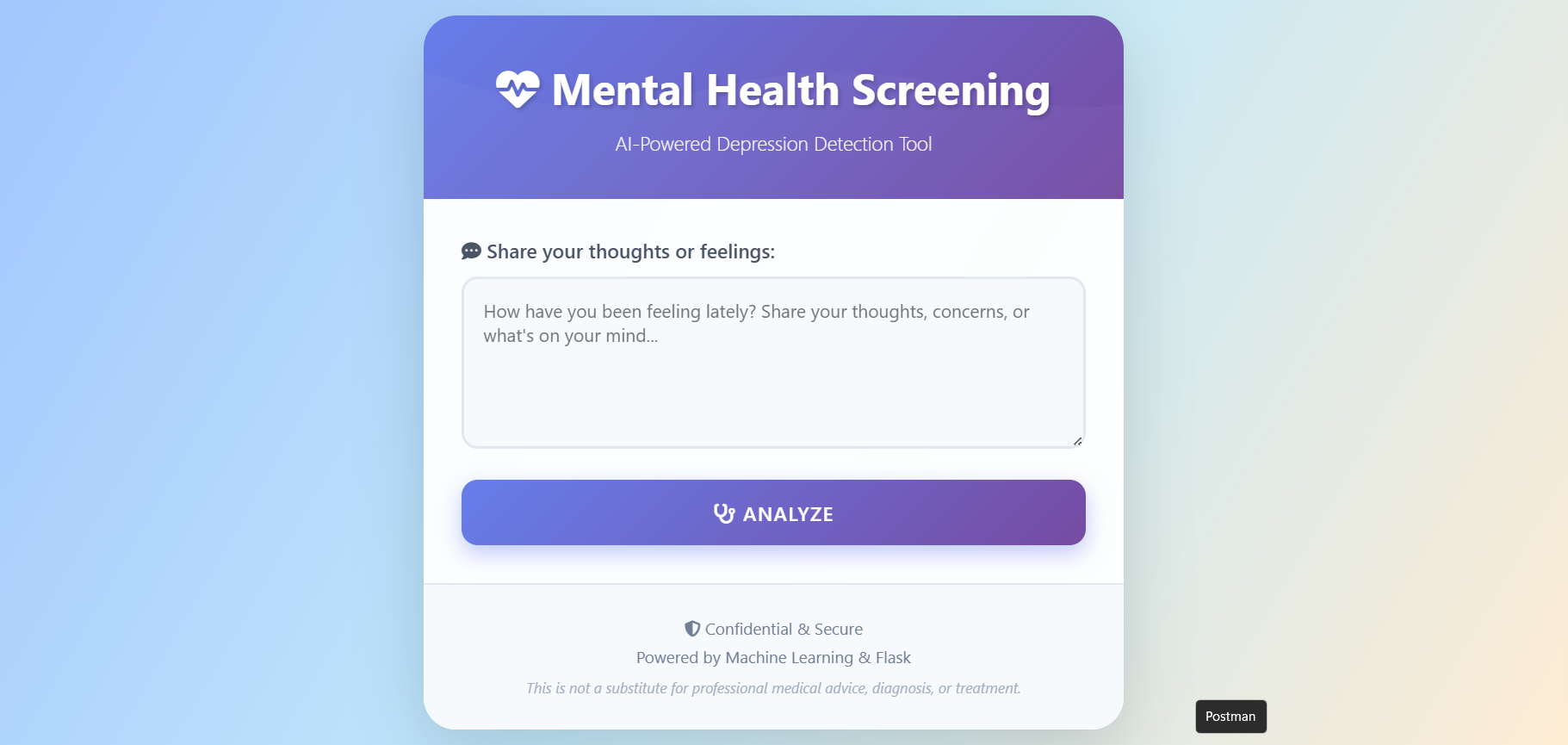
ML-based depression detection system using text analysis and Random Forest classification
About the Project
Study project for learning machine learning and data science fundamentals
Text-based depression detection using Random Forest classifier trained on mental health dataset
Character-level TF-IDF features (7-grams) for robust text analysis without extensive preprocessing
Comprehensive model comparison: tested 10 algorithms including Naive Bayes, SVM, and ensemble methods
Flask web application with real-time prediction API deployed on PythonAnywhere
Systematic hyperparameter tuning with results exported to Excel for analysis
Key Highlights
Trained Random Forest classifier achieving high accuracy on mental health text classification
Implemented character 7-gram TF-IDF vectorization for feature extraction from raw text
Conducted extensive hyperparameter tuning across 10 ML algorithms with grid search
Built Flask REST API for real-time depression risk prediction from user text input
Applied text length filtering (60-3000 characters) and stratified train-test splitting
Evaluated models using accuracy, precision, recall, F1-score, and confusion matrices
Deployed production model with joblib persistence for consistent inference pipeline